
Hvordan går man frem for å estimere overdødelighet over tid? Dette er nyttig ettersom det kan svare på spørsmål om hvor dødelig pandemien var i 2020-2021, så vel som effekten av vaksinen brukt for å redusere disse dødsfallene. I denne analysen, begrenser vi oss til aldersgruppen 65+ siden denne aldersgruppen har økt risiko for å dø og er mer følsomme for endringer i det indre og ytre miljøet. Norge er et interessant land å studere siden det hadde en relativt lav dødelighet i den innledende pandemibølgen i mars 2020 og har god statistikk tilgjengelig for analyse fra Statistisk Sentralbyrå (SSB). Sammen med den relativt lille befolkningen gjør dette Norge til en god kandidat til å teste nøyaktighetsmarginen på estimatet. Denne marginen kalles også et konfidensintervall, og kan tolkes som sannsynligheten for at observasjonen er et resultat av tilfeldig variasjon. For eksempel, et 95% konfidensintervall betyr at 1 av 20 observasjoner kan forventes å være utenfor intervallet. I dette tilfellet er dette snakk om en ukentlig observasjon som er utenfor intervallet sammenlignet med samme uke i andre år.
Vi bruker også alle dødsårsaker siden disse ikke har noen skjevfordeling med hensyn til diagnostisering, selv om vi har tatt forbehold for covid-dødsfall helt til slutt.
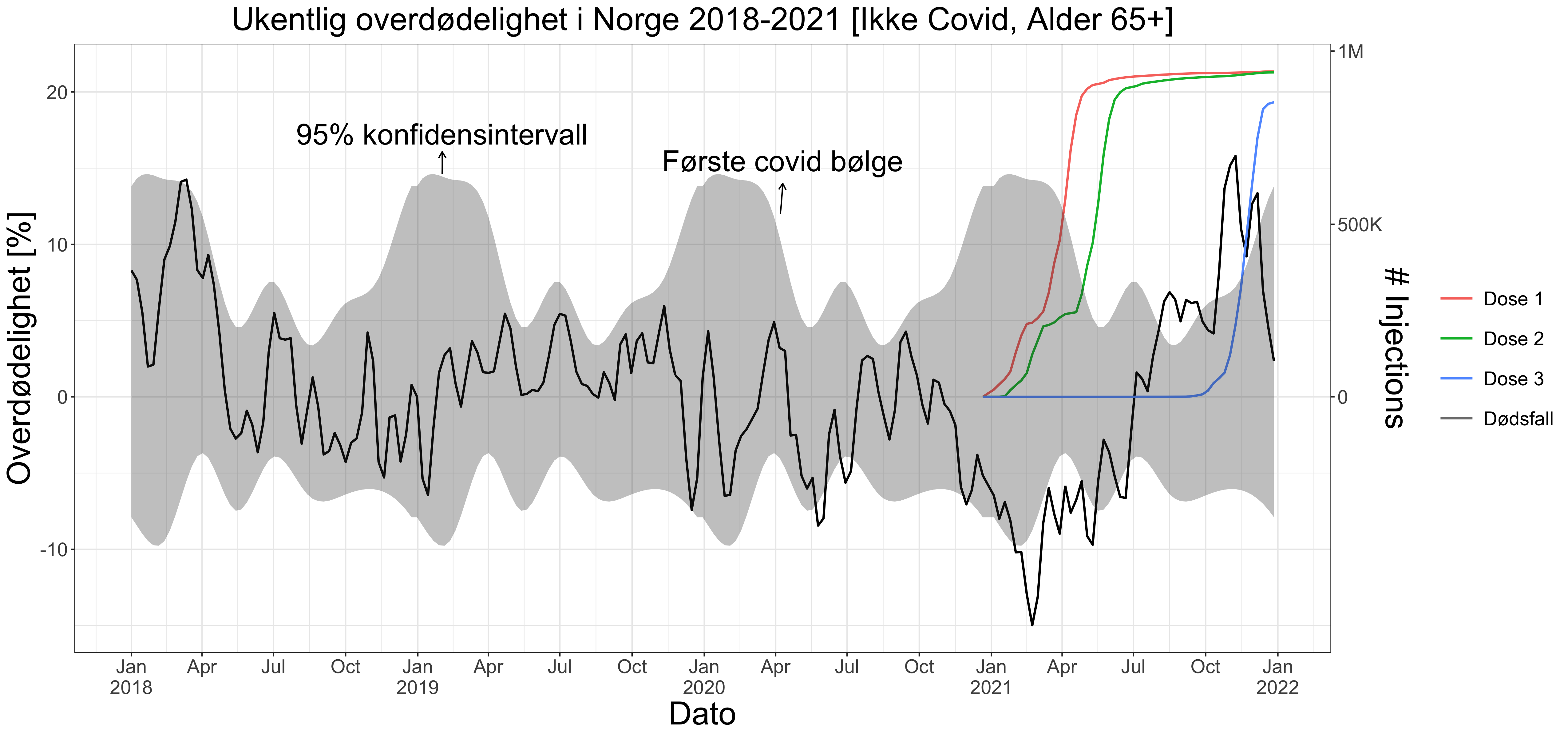
Etter vår statistiske analyse ser vi at den første pandemibølgen var så vidt over det normale mens siste halvdel av 2021 hadde en markant høy dødelighet (Figur 1). Vi ser også at vaksinen ikke nødvendigvis har begrenset dødsfall i 2021, selv om det er vanskelig å trekke faste konklusjoner. Ettersom pandemibølgen faktisk startet litt under basisestimatet, kan det være et tegn på at overdødelighetsestimatet er konservativt. Første halvdel har en dødelighet under basisestimatet. Det kan tenkes at den høye dødeligheten på slutten av året er etterslep på den tidligere lave dødeligheten, men det er 35% av ukene i 2021 som er over 95% konfidensintervallet, mens bare 23% er under. Vi bruker 95% som en konservativ grense for hva som er normalt. Dette estimatet kan tolkes som grensen man må over for at det er 5% sjanse for at estimatet er høyt ved en tilfeldighet eller tilfeldig variasjon, basert på tidligere dødelighetstall som vi her inkluderer med årene 2001-2021 (se Figur 5).
Vi estimerer basisestimatet basert på tiårig – og sesong-baserte trender, ved å minimere distansen fra avvikene til denne trenden. Denne trenden kalles den 50. kvantilen, eller medianen. Dette er beskrevet i detalj i neste seksjon.
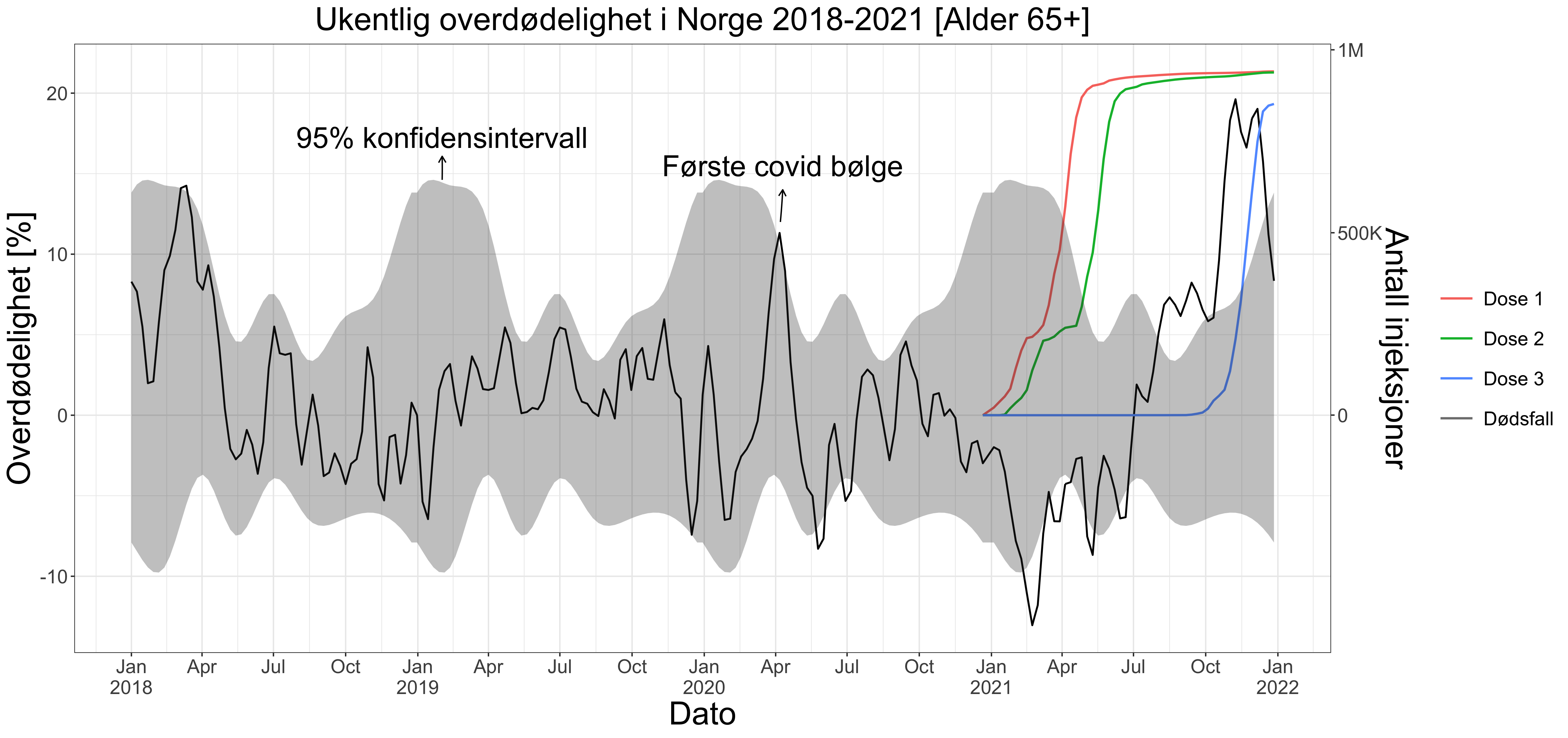
Fordi vi bruker observasjonsbaserte kvantiler i konfidensestimatet vil det være en vertikal asymmetri over og under basisestimatet (x-aksen i Figur 1). Fordelen med denne metodikken er at vi får nøyaktig konfidensdekning på observasjonene, som testes i perioden 2001-2019.
Statistisk metodikk
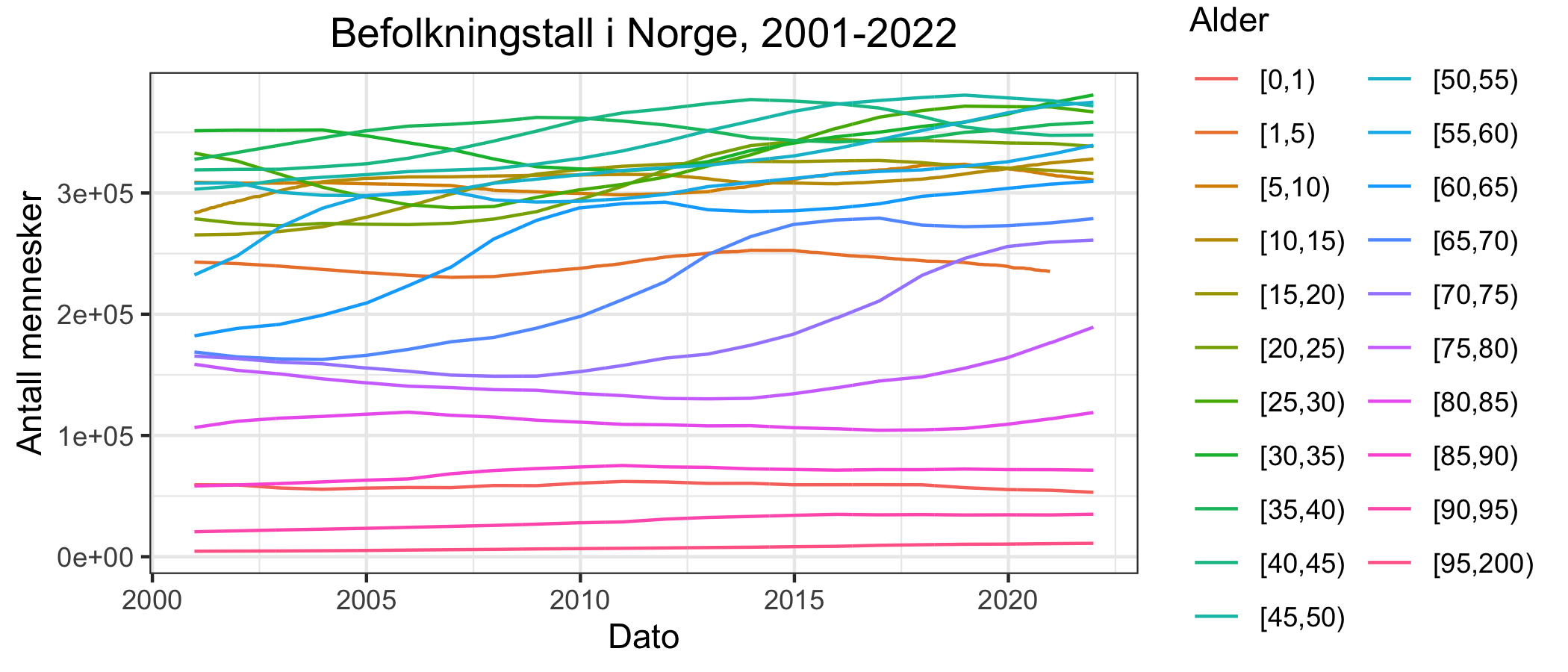
For å estimere overdødelighet er det nødvendig å bruke aldersstandardisert dødelighet ved først å estimere dødeligheten for hver aldersgruppe. Det vil også gjøre at hver aldersgruppe er uavhengig av hverandre siden vi korrigerer for befolkningstall. Befolkningsdata samles inn for hvert år og interpoleres med et ukentlig intervall. En relativt jevn befolkningsendring oppnås for hver aldersgruppe, med de største aldersgruppene i de yngre parentesene (Figur 2). Disse befolkningsantallene gjør det mulig å beregne dødelighetsrater (Figur 3).
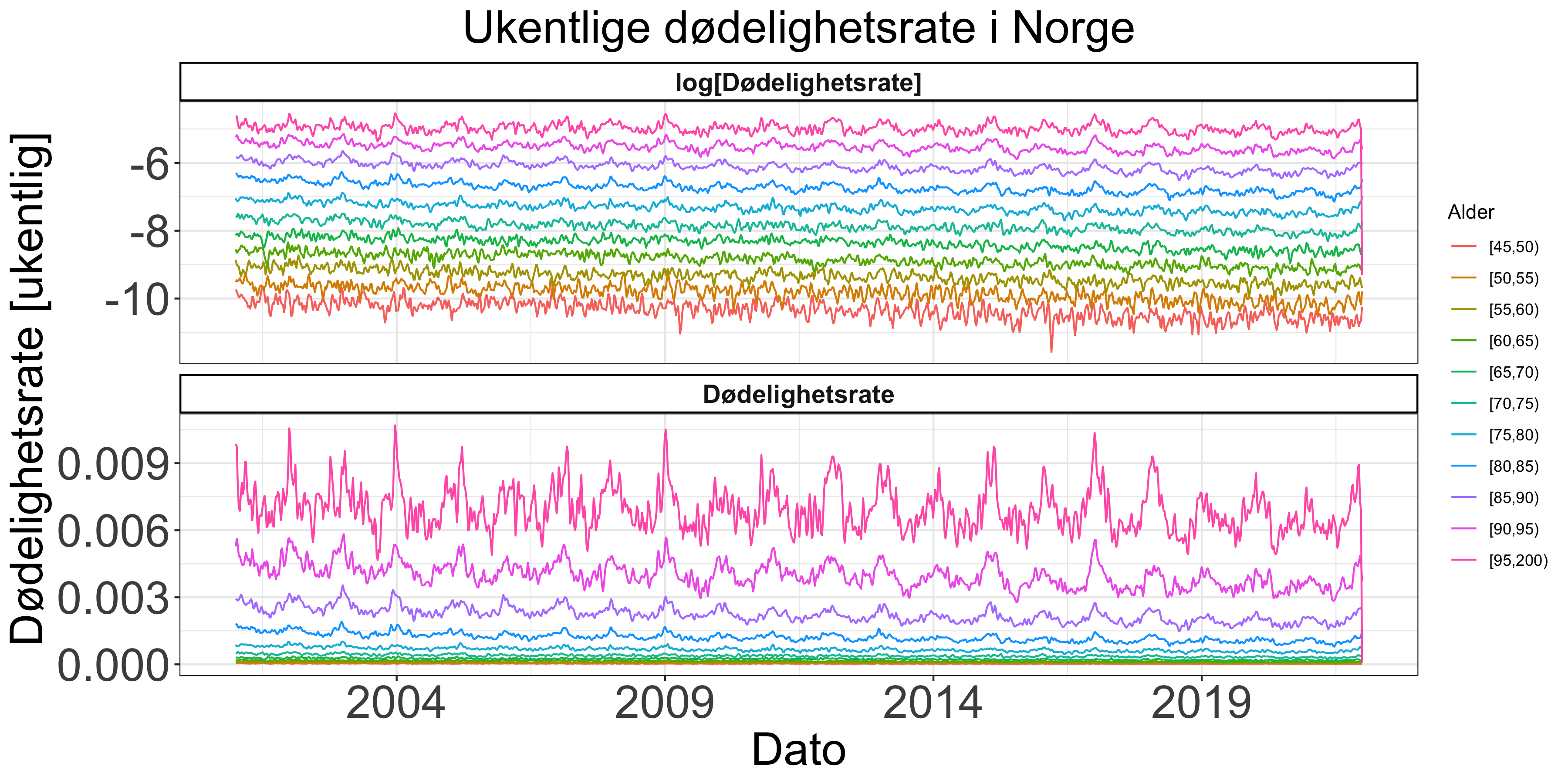
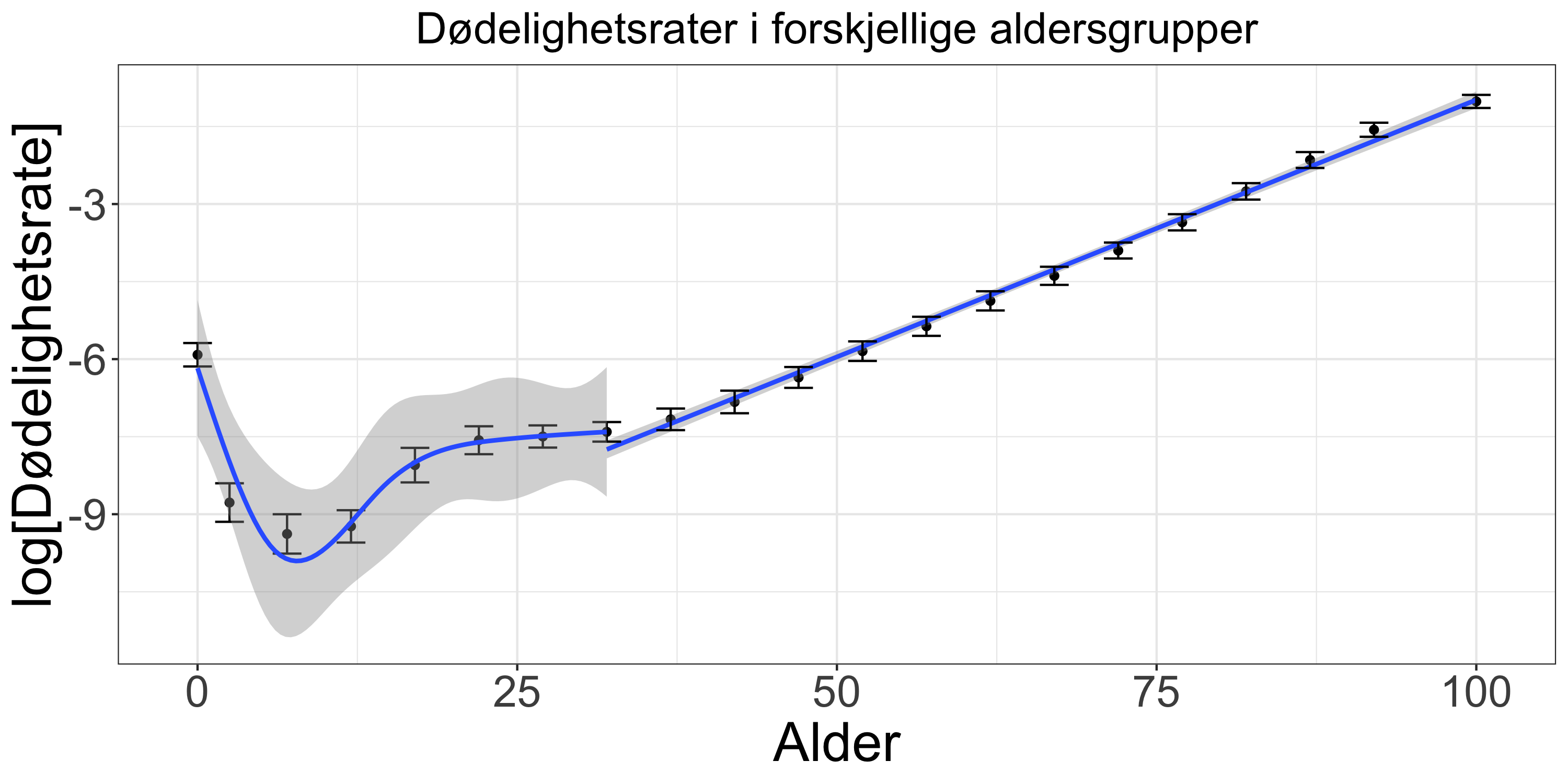
Det viser seg at dødelighetsrater øker eksponensielt med alder etter ca. 25 år (Figur 4), et velkjent fenomen som først ble oppdaget av Gompertz i 1825 (Winsor 1932). Loven kan tolkes som at overlevningsraten synker i en geometrisk sekvens for hvert år som går til den går til null. En annen ting som er interessant er at variansen er rimelig konstant i de voksne aldersgruppene, men bare i dette logg-transformerte domenet, som viser til at det er i dette domenet vi burde gjøre vår analyse, som også gjøres av andre (f. eks. N. Islam (2021)). Merk også at barnegruppene har både høyere varians og en mer uforutsigbar trend.
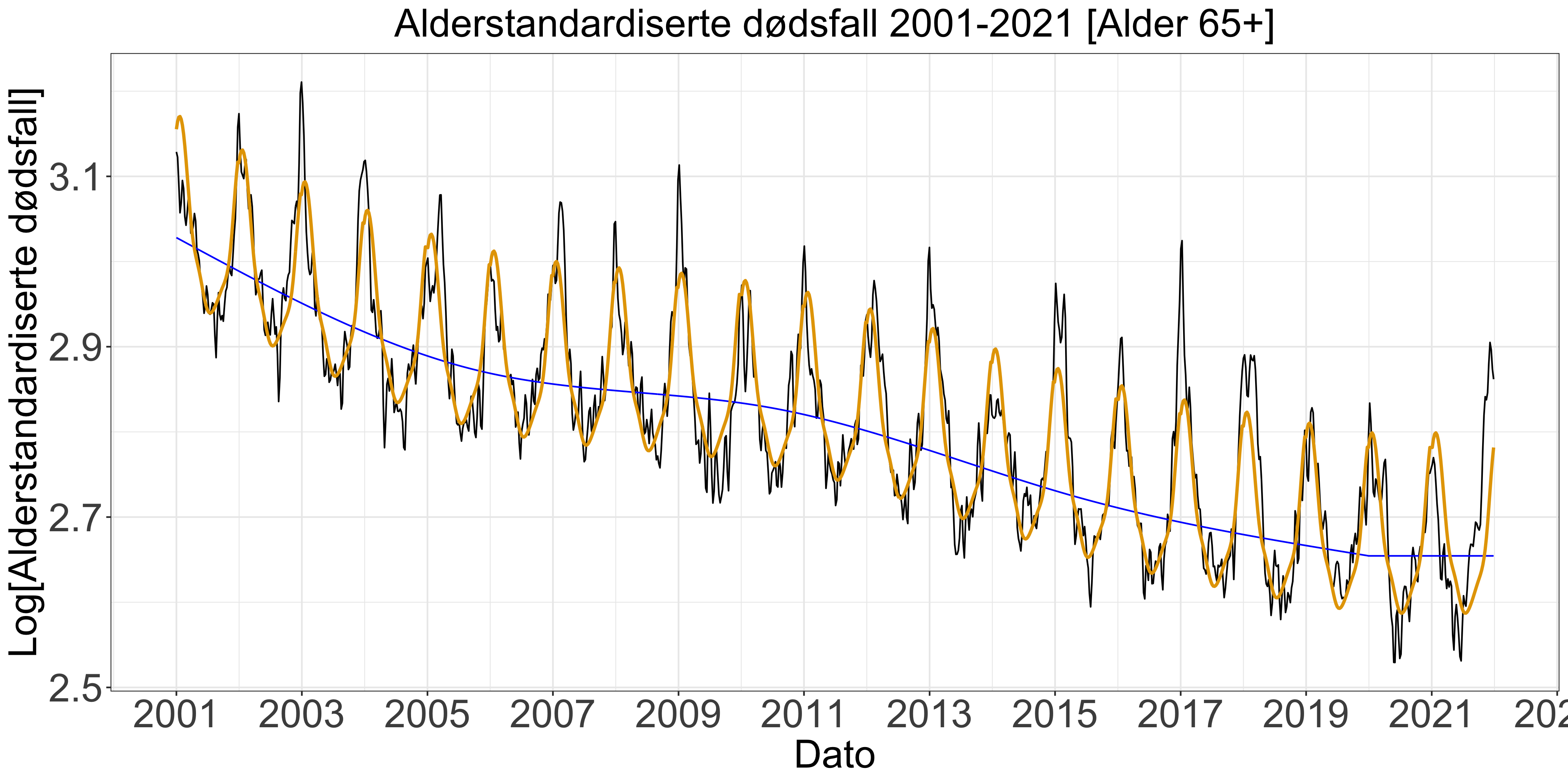
Med alderstandardiserte rater kan vi summere aldersgrupper med den Europeiske aldersgruppemalen (European Standard Population, ESP), som har en befokningsfordeling for en standard befolkning på 100,000 mennesker (se f.eks. Public Health Scotland). Summen av de relevante aldersgruppene viser at vi har hatt en generell nedgang i dødsfall i disse aldersgruppene de siste 20 årene (Figur 5).
For å estimere en trendlinje bruker vi en model som har både en tiårig og en sesongbasert trend, der begge antas å være tredjegrads polynomer (også kalt “splines”). Med disse polynomene finner vi estimatet ved å minimere de absolutte avviksdistansene fra trendlinjen, som kalles kvantilregresjon. For å være ekstra konservativ anntar vi at det er en konstant tiårstrend etter 2020.
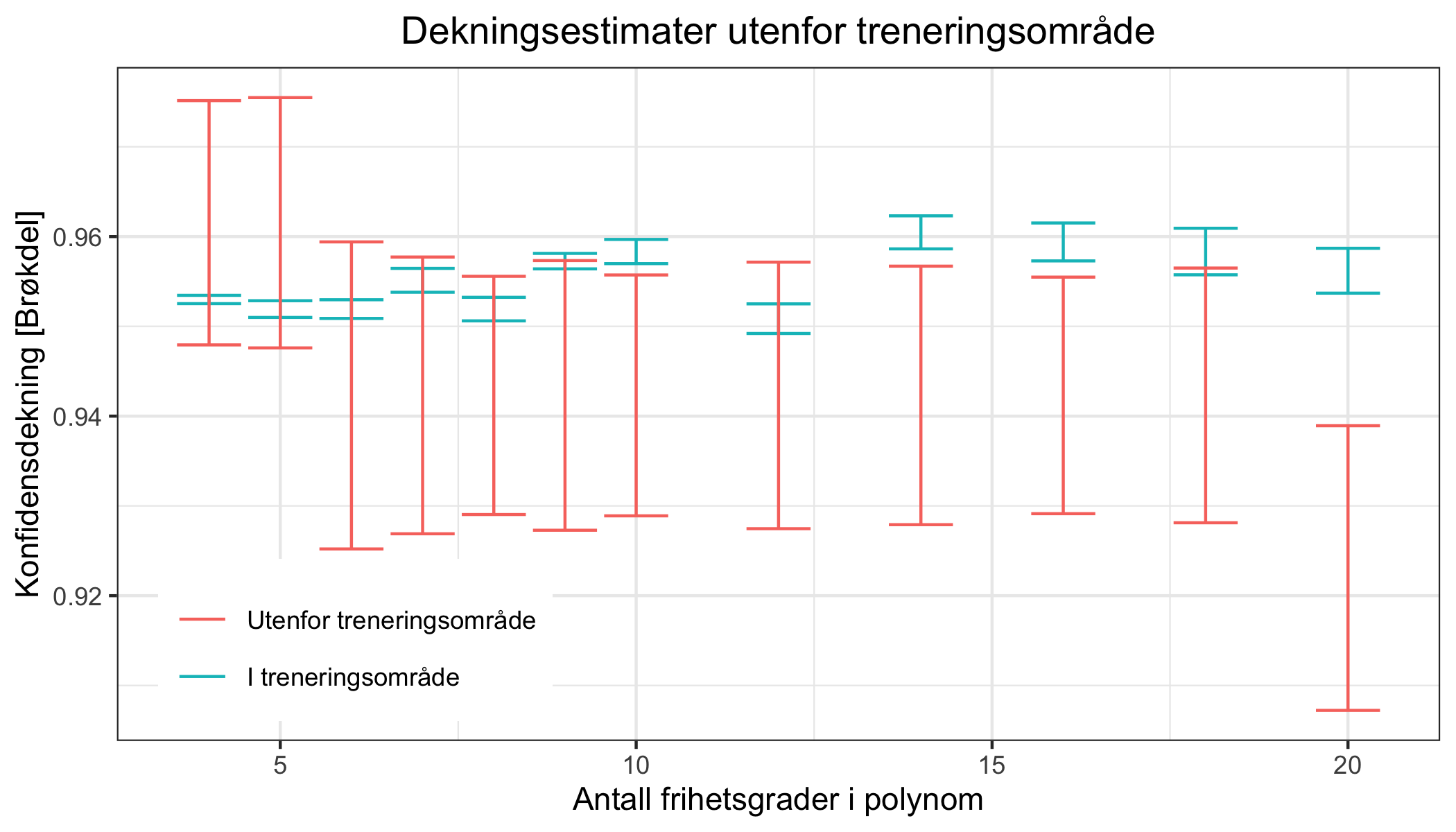
Fordi Norge har gode statistiske kilder har vi observasjoner helt tilbake til 2001, noe man kan bruke til å estimere dekningen til konfidensintervallet ved å variere modellens kompleksitet. Det kan gjøres på følgende måte:
- Estimer en tiårig trend men kvantilregresjon fra 2001-2019 og trekk fra denne trenden så alle år er på samme basisnivå.
- Fjern et år og estimer på samme måte sesongtrenden samt konfidenskvantiler, 2.5% og 97.5%.
- Beregn hvor mange observasjoner i teståret som er utenfor konfidensintervallet.
- Gjenta steg 2-3 for alle år og oppsummer resultat.
- Gjenta steg 2-4 med forskjellige frihetsgrader i polynomene.
- Den frihetsgraden som er minst og dekker det antatte konfidensintervallet er den mest sparsommelige modellen med nøyaktig dekning.
Vi gjør denne estimeringsprosessen og ser at 6-8 frihetsgrader er en god modellkompleksitet, sett at denne modellen dekker 95% av observasjonene i en periode modellen ikke er trenert på (Figur 6). Slik kan man da si med økt sikkerhet at konfidensintervallet er stødig i perioden etter 2020. Disse konklusjonene holder også om man tar ut Covid-dødsfall fra observasjonene (Figur 7).
Av Lov og Helses forskerteam
Vi i Lov og Helse verdsetter deres tilbakemeldinger og som dere vet er ytringsfriheten kompromissløs hos oss. Vi ønsker et rom der alle stemmer kan komme til uttrykk. Vi praktiserer ingen sensur, og vi ønsker å moderere minst mulig.
Samtidig ønsker vi å bevare et kommentarfelt som oppleves konstruktivt, relevant og respektfullt for dem som vil diskutere innholdet i artiklene. Når trådene blir fylt med innlegg som går langt utenfor temaet, eller domineres av én stemme over tid, så kan det gjøre det vanskeligere for andre å delta.
Vi oppfordrer derfor alle til:
– Å holde seg mest mulig til temaet i artikkelen
– Å stille spørsmål og komme med innspill som bygger videre på hverandres tanker
– Og å bidra til en god og åpen tone, hvor alle føler seg velkommen
Vi har stor takhøyde og rom for ulike perspektiver – det ønsker vi å beholde. Samtidig vil vi bidra til at samtalen blir meningsfull og relevant for flest mulig.
Takk for at du er med i samtalen – på en konstruktiv og inkluderende måte.
– Redaksjonen i Lov og Helse